robots.txt文件站長們應該都不陌生,正確的robots.txt文件對于網站來說是非常重要的,作用是告訴搜索網站哪些地方可以抓取,哪些地方不可以抓取。
“wordpress網站如何建立robots.txt文件”這篇文章詳細介紹過wordpress網站robots.txt文件,大家可以先看看這篇文章,以便于能更好的理解robots.txt文件。
robots.txt文件雖然簡單但也是極易出錯的,一個字符的錯誤就會影響整個網頁收錄效果,阻止搜索引擎索引網站頁面,robots.txt文件錯誤率非常高,即使是經驗豐富的網站優化人員也避免不了。
你認真理解完這篇文章將可以學到以下內容:
1、robots.txt文件是什么;
2、robots.txt長什么樣;
3、robots.txt用戶代理和指令;
4、網站什么時候你需要robots.txt文件;
5、如何找到網站robots.txt文件;
6、如何建立一個robots.txt文件;
7、robots.txt的寫法;
8、robots.txt文件示例;
9、如何檢測robots.txt文件中的問題。
robots.txt文件是什么?
robots.txt文件是搜索引擎抓取網站的第一個文件,作用是告訴搜索蜘蛛網站哪些頁面可以抓取,哪些頁面不可以抓取,robots.txt文件規則中列出了所有禁止或允許搜索蜘蛛抓取的網站頁面,還規定了搜索蜘蛛(非Google谷歌搜索)該怎樣抓取網站內容。
重要提示:
大部搜索蜘蛛都會遵守robots.txt文件規則,而有少部分搜索蜘蛛則無視robots.txt文件規則,百度和谷歌搜索都會遵守robots.txt文件規則。
Robots.txt長什么樣?
以下這網站robots.txt文件基本格式:
Sitemap: [URL location of sitemap]
User-agent: [bot identifier]
[directive 1]
[directive 2]
[directive …]
User-agent: [another bot identifier]
[directive 1]
[directive 2]
[directive …]
如果你以前沒有了解過robots.txt文件,你初次看它可能會覺得很難,但其實只要弄懂了robots.txt文件語法格式就非常簡單了,簡單地講你可以在robots.txt文件中規則搜索蜘蛛網站哪些頁面可以抓取,哪些頁面不可以抓取,下面黑帽百科來給大家詳細介紹下。
User-agents(用戶代理)
每個搜索引擎都有一個特定的用戶代理,可在網站robots.txt文件中針對不同的用戶代理分配不同的抓取規則,搜索引擎用戶代理大概有上百種,以下是對網站SEO優化有用的用戶代理:
Google: Googlebot
Google Images: Googlebot-Image
Bing: Bingbot
Yahoo: Slurp
Baidu: Baiduspider
DuckDuckGo: DuckDuckBot
robots.txt文件中所有用戶代理均嚴格區分大小寫,但你也可以使用通配符(*)一次性為所有用戶代理制定搜索蜘蛛抓取規則。
下面來給大家舉個例子,如果你想屏蔽所有的搜索蜘蛛,可參考以下robots.txt文件寫法:
User-agent: *
Disallow: /
User-agent: Googlebot
Allow: /
在網站robots.txt文件中,你可以指定多個用戶代理,每指定一個新的用戶代理,它都是獨立的,簡單地講如果你在robots.txt文件中為多個用戶制定規則,那么第一個用戶代理規則并不適用于第二個,第二個并不適用于第三個,依此類推。
需要注意的是,如果你為同個用戶代理制定了多次規則,那么這些規則將會被放在一起執行。
重要提示:
搜索蜘蛛只會遵守表述準確且詳細的用戶代理指令,因此上面的robots.txt文件會禁止除谷歌蜘蛛外所有搜索蜘蛛的抓取,谷歌搜索蜘蛛會忽略一些不太準確詳細的用戶指令聲明。
Directives(指令)
robots.txt文件指令指的是你希望搜索蜘蛛遵循的規則。
目前支持的指令
下面是目前谷歌蜘蛛支持的robots指令及谷歌搜索的用法。
Disallow指令
使用此robots指令可以禁止搜索蜘蛛訪問某個文件或頁面,例如你想禁止搜索蜘蛛訪問你的博客目錄及博客帖子頁面,則robots.txt文件就可以像下面這樣寫:
User-agent: *
Disallow: /blog
注意:如果你在robots.txt文件的Disallow指令后沒有寫任何路徑,則搜索蜘蛛就會忽視它。
Allow指令
使用此Allow指令是規定搜索蜘蛛訪問網站某個文件或者頁面,即使被disallow指令屏蔽了仍然可以使用,如果你屏蔽特定文章以外的所有網站頁面,那么robots.txt文件就可以這樣寫:
User-agent: *
Disallow: /blog
Allow: /blog/allowed-post
在以上這個robots.txt文件規則中,是允許搜索蜘蛛抓取/blog/allowed-post這個目錄的,但不允許搜索蜘蛛抓取
/blog/another-post、/blog/yet-another-post、/blog/download-me.pdf這些目錄,谷歌和百度搜索都是支持此指令的。
注意:和Disallow指令一樣,如果你在allow指令沒有加任何路徑,那么搜索蜘蛛也會忽略它。
robots.txt文件規則說明:
編寫robots.txt文件規則需要非常細心,否則disallow指令與allow指令沖突了你都不知道,如下方所示,我們在robots.txt文件中阻止了搜索蜘蛛抓取/blog/這個目錄,但同時也開放了/blog這個目錄的抓取。
User-agent: *
Disallow: /blog/
Allow: /blog
在以上這個robots.txt文件中/blog/post-title/這個目錄被禁止抓取了,但Allow: /blog
這段以開放了/blog
目錄的抓取,那么搜索蜘蛛到底執行哪個指令呢?
谷歌和必應搜索一般會執行較長那個指令,在以上這個例子中會執行disallow指令。
Disallow: /blog/ (6 字符)
Allow: /blog (5 字符)
在以上這個例子中,disallow和allow指令長度是一樣的,那么限制較小的范圍就會被執行,以上這個例子會執行Allow指令。
提示:由于Allow: /blog中/blog后面沒有斜杠,則是被認為可以抓取的,嚴格來說只適用于谷歌搜索和必應搜索,其它的搜索會執行第一條指令,也就是會執行disallow指令。
Sitemap指令
使用sitemap指令可標記網站地圖文件,如果你對網站xml地圖還不是特別熟悉,sitemap網站地圖文件包含了該網站可被搜索蜘蛛抓取索引的所有網站頁面鏈接。
以下就是某個網站robots.txt文件中Sitemap指令:
Sitemap: https://www.zhuzhouren.cn/sitemap.xml
User-agent: *
Disallow: /blog/
Allow: /blog/post-title/
網站robots.txt文件中標明了sitemap指令的重要性,如果你已向搜索站長平臺提交了網站地圖文件,那么這個步驟就可以省略掉,對于其它搜索平臺,例如必應搜索,就需要明確標明網站地圖文件在什么位置,這個步驟是非常重要的,這里我們需要注意的是不需要針對不同代表用戶標注不同的sitemap指令,所以我們只需要將sitemap指令標注在robots.txt文件在最開始或最末尾處,如以下這樣:
Sitemap: https://www.zhuzhouren.cn/sitemap.xml
User-agent: Googlebot
Disallow: /blog/
Allow: /blog/post-title/
User-agent: Bingbot
Disallow: /services/
谷歌搜索、百度搜索、Ask、必應、雅虎搜索都支持sitemap指令,你也可以在robots.txt文件中寫多條sitemap指令。
不再支持的指令
下面是谷歌搜索不支持的指令,由于技術原因這部分指令一直沒有被支持過。
Crawl-delay指令
可用這個指令來指定搜索蜘蛛抓取的間隔時間(秒),例如你希望搜索蜘蛛在每次抓取網站頁面后等待5秒鐘,那以你就可以這樣寫,如下所示:
User-agent: Googlebot
Crawl-delay: 5
谷歌搜索不支持以上這個指令,但必應和Yandex搜索是支持此指令的。
注意你在設置這個指令的時候要特別小心,特別是大中型網站,否則會限制網站頁面抓取,例如你將Crawl-delay指令設置為5,那么搜索蜘蛛只能抓取你網站17,280個網站頁面,如果你的網站大型網站,那么這個抓取量是非常小的,如果你的網站為小型網站,則不需要管,還可以幫你的網站省流量帶寬。
Noindex指令
noindex指令從來就沒有被谷歌搜索支持過,近年來,有些人認為谷歌有一些“處理不受支持和未發布的規則的代碼(例如noindex)”,所以如果你想阻止谷歌搜索抓取你的網站某個目錄頁面,你可以使用此指令:
User-agent: Googlebot
Noindex: /blog/
在2019年9月1日,谷歌搜索就表示不支持此指令,但如果你想禁止搜索蜘蛛抓取某個目錄頁面的話,你可以使用meta robots標簽或x-robots HTTP頭部指令。
Nofollow指令
nofollow指令谷歌搜索也從來沒有支持過,這個標簽谷歌搜索以前是用來阻止搜索蜘蛛抓取另一個鏈接的,例如你想禁止谷歌搜索抓取你的博客目錄頁面,你就可以這樣設置:
User-agent: Googlebot
Nofollow: /blog/
谷歌搜索在2019年9月1表示說不支持這個robots指令,如果你想禁止搜索蜘蛛抓取此頁面上的所有鏈接,你可以使用meta robots標簽或x-robots HTTP頭部指令,如果你想讓谷歌搜索不追蹤某個鏈接,那么你可以在這個url超級鏈接中加入rel=”nofollow”參數,加入了這個參數,搜索蜘蛛就不會追蹤這個鏈接了。
你需要一個Robots.txt文件嗎?
對于有些網站來說,有無robots.txt文件無所謂,特別是一些小網站,雖然有沒有robots.txt文件都差不多,但卻沒有理由不去擁有它,因為網冰點robots.txt文件可以控制搜索蜘蛛哪些網站文件或目錄可以抓取,哪些不可以抓取,網站robots.txt文件作用主要有以下幾個:
1、防止搜索蜘蛛抓取收錄重復頁面;
2、禁止網站在某個階段不被搜索蜘蛛抓取;
3、禁止搜索蜘蛛抓取網站某個文件或目錄;
4、防止網頁服務器過載;
5、防止網頁浪費了搜索蜘蛛抓取預算;
5、防止用戶隱私被抓取。
百度或谷歌搜索一般不會抓取robots.txt文件所禁止的內容,但沒有辦法保證robots.txt文件禁止的內容就一定不會被搜索蜘蛛抓取,例如,谷歌搜索曾經就表示過,如果搜索蜘蛛從另外途徑獲得了robots.txt文件禁止頁面內容鏈接,那么就有可能將robots.txt文件禁止的內容展現在搜索結果中。
如何找到你的robots.txt文件?
網站robots.txt文件直接存儲在網站根目錄中,例如通過域名.com//robots.txt就可以直接訪問網站robots.txt文件,看到下圖中類似的信息,這個就是網站robots.txt文件內容。

如何建立一個robots.txt文件?
如果你網站沒有robots.txt文件,想要新建一個robots.txt文件,其實也是非常簡單的,首先新建一個.txt文件,然后按照要求填寫如下robots指令,例如你不希望搜索蜘蛛抓取/admin/這個目錄,就可以像以下這樣進行設置:
User-agent: *
Disallow: /admin/
你還可以繼續添加robots指令,只到滿足你的要求為止,然后將文件保存為robots.txt,為了避免robots文件語法錯誤,建議使用百度站工具對robots.txt文件進行校驗,如下圖所示:
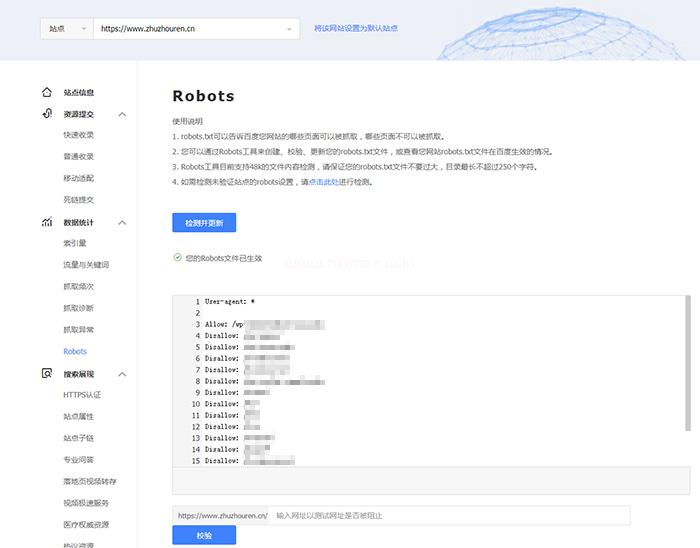
此步驟非常重要,可以避免由于robots文件語法錯誤給網站帶去嚴重的后果。
在哪里放置robots.txt文件呢?
將robots.txt文件放在網站根目錄中,例如你的網站域名為zhuzhouren.cn,那么robots.txt文件就可以用zhuzhouren.cn/robots.txt這個url地址訪問到。
如果你的網站域名為二級域名,例如blog.zhuzhouren.cn,那么robots.txt就可能通過blog.zhuzhouren.cn/robots.txt進行訪問。
Robots.txt的寫法
每一個新指令都需要另起一行
每一個robots指令都占據一行,否則會讓搜索蜘蛛理解錯誤:
錯誤示例:
User-agent: * Disallow: /directory/ Disallow: /another-directory/
標準示例:
User-agent: *
Disallow: /directory/
Disallow: /another-directory/
使用通配符簡化指令
我們不但可以使用通配符(*)指令應用于所有用戶代理,還可以使用通配符(*)指令來匹配類似的URL地址,例如,你想禁止搜索蜘蛛訪問網站參數化url地址,你可以像以下這樣進行設置:
User-agent: *
Disallow: /products/t-shirts?
Disallow: /products/hoodies?
Disallow: /products/jackets?
…
但以這種方法太過于復雜,我們可以將其簡化成以下這樣:
User-agent: *
Disallow: /products/*?
以上這個robots指令代表的意思是禁止所有搜索蜘蛛抓取/product/目錄下所有帶問號(?)的url鏈接,簡單地講就是禁止搜索蜘蛛抓取/product/目錄下所有帶問號(?)的url鏈接。
使用美元符號($)來標注以特定字符結尾的URL
”$”美元符號是robots指令結尾特定字符,例如你想禁止搜索蜘蛛抓取所有.pdf格式的url鏈接,那么你的robots.txt文件可以這樣進行設置,如下所示:
User-agent: *
Disallow: /*.pdf$
以上robots文件指令代表的意思是禁止搜索蜘蛛抓取任何以.pdf為結尾的url鏈接,例如無法抓取/file.pdf這樣的文件,但可以抓取/file.pdf?id=68937586,因為這個文件不是以.pdf結尾的。
相同的用戶代理只聲明一次
如果你在robots文件中多次聲明了相同的用戶代理,谷歌搜索雖然沒有表示說反對這樣的申明,但卻是可以在一起執行的,如下所示:
User-agent: Googlebot
Disallow: /a/
User-agent: Googlebot
Disallow: /b/
谷歌蜘蛛不會索引以上robots文件指令中的任何一個目錄。
雖然谷歌搜索沒有表示說不能這么做,但卻為了不給搜索蜘蛛困惑,建議只聲明一次就行了。
使用精準的指令避免以外的錯誤
如果你使用精準的robots文件指令,很有可能會給網站優化帶去很嚴重的錯誤,例如下方robots.txt文件指令本意是只禁止搜索蜘蛛抓取/de/目錄中的內容:
User-agent: *
Disallow: /de
但是這個robots.txt文件指令同時也禁止了搜索蜘蛛抓取以/de開頭的目錄內容,如下方所示:
/designer-dresses/
/delivery-information.html
/depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
以上這種問題我們只需要多加一個斜杠就行了,如下方所示:
User-agent: *
Disallow: /de/
使用注釋給開發者提供說明
注釋功能可以向開發者說明robots.txt文件指令的作用,如下方所示:
# This instructs Bing not to crawl our site.
User-agent: Bingbot
Disallow: /
搜索蜘蛛會忽略所有以“#”井號開頭的robots.txt文件指令。
針對不同的子域名使用不同的robots.txt文件
robots.txt文件只限于當前根目錄域名所使用,如果你需要設置其它的域名的robots.txt文件規則,那么就需要設置多個robots.txt文件規則。
例如,當前主站域名為www.zhuzhouren.cn,而你的博客二級域名為blog.zhuzhouren.cn,那么這種情況就需要設置多個robots.txt文件,一個放在主站根目錄下,一個放在博客網站根目錄下。
Robots.txt文件示例
下面的robots.txt文件示例,主要是給站長們一些參考,如果這些robots.txt文件指令正好與你要求一樣,那么你可以將以下robots指令復制粘貼到txt文件中,將其另存為robots.txt文件上傳至網站根目錄中。
以上robots指令代表的意思是允許所有搜索蜘蛛訪問網站所有頁面:
User-agent: *
不允許任何搜索蜘蛛抓取網站任何頁面
User-agent: *
Disallow: /
禁止所有搜索蜘蛛抓取/folder/這個目錄。
User-agent: *
Disallow: /folder/
禁止所有搜索蜘蛛抓取/folder/這個目錄,但保留/folder/目錄下page.html這個頁面可以抓取。
User-agent: *
Disallow: /folder/
Allow: /folder/page.html
禁止所有搜索蜘蛛抓取this-is-a-file.pdf這個文件
User-agent: *
Disallow: /this-is-a-file.pdf
禁止所有搜索蜘蛛抓取網站pdf文件
User-agent: *
Disallow: /*.pdf$
禁止谷歌蜘蛛抓取帶參數的url頁面。
User-agent: Googlebot
Disallow: /*?
如何檢測robots.txt文件中的問題?
robots.txt文件是非常容易出錯的,所以對robots.txt文件的校驗也是非常有必要的,下面黑帽百科來給大家講講robots.txt文件常見錯誤,包括robots文件指令的含義及解決辦法:
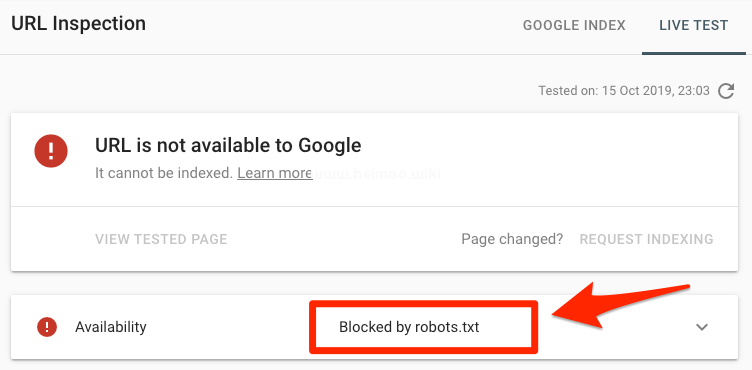
檢驗網站某個目錄頁面是否有錯誤,你可以將robots.txt文件中屏蔽的目錄或文件放入Search Console(谷歌資源管理器)的URL Inspection tool(網址檢測),如果顯示被robots.txt文件屏蔽了,就如下方所示:
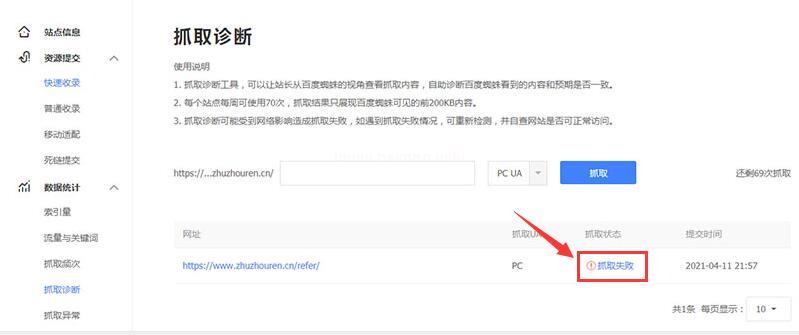
國內用戶使用百度站長平臺也可以進行檢測,如下圖所示:
顯示該目錄被robots.txt屏蔽了,如下圖所示:
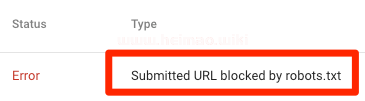
上圖中意味著此鏈接在Sitemap文件當中,至少有一條url鏈接被robots.txt屏蔽了。
如果你的網站地圖sitemap文件是正確的,頁面中并不包含canonicalized、noindexed、redirected等標簽,而且你所提交的sitemap文件鏈接沒有被robots.txt屏蔽,如果檢測這個頁面鏈接確實被屏蔽了,那么就需要檢查被屏蔽的頁面,再調整robots.txt文件,刪除相應的robots指令。
檢測網站目錄有沒有被屏蔽,你可以使用谷歌的robots.txt檢測工具和百度站長平臺robots文件檢測工具來檢測robots指令,在修改robots指令的時候也需要特別小心,因為你的修改會影響網站其它目錄頁面或文件。
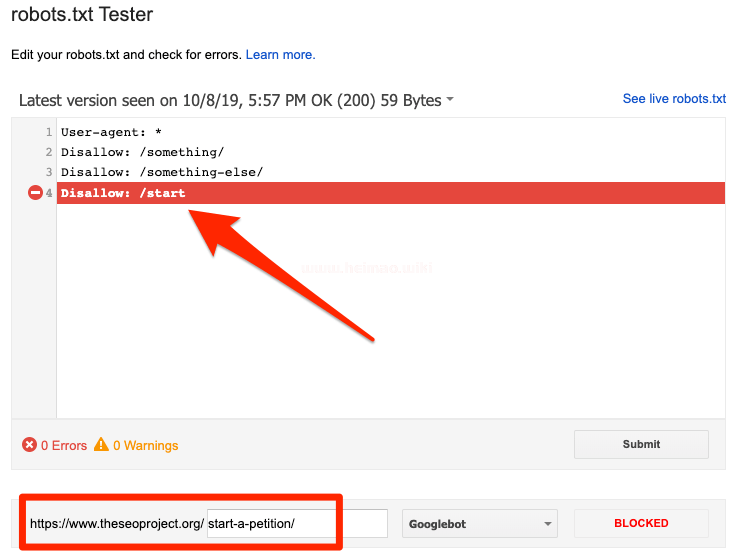
從上圖中可以看出帶有start的網站目錄都被robots.txt屏蔽了

上圖中代表的意思是帶有start的網站內容都被robots.txt屏蔽了,暫時屏蔽了谷歌蜘蛛索引。
被robots指令禁止索引的內容是需要被搜索蜘蛛抓取的內容,那么我們只需要刪除錯誤的robots指令即可,此時你需要注意此內容是否被robots文件標記為禁止索引狀態,如果禁止索引的內容是不需要被索引的內容,那么就可以刪除屏蔽索引指令,然后使用meta robots標簽、x-robots HTTP頭部指令進行屏蔽,保證此頁面內容不被搜索蜘蛛索引。
注意,如果你想將被屏蔽抓取的內容從禁止索引庫中刪除,首先必須要刪除抓取阻礙,否則搜索蜘蛛是無法抓取頁面內容的。
索引但是被robots.txt屏蔽
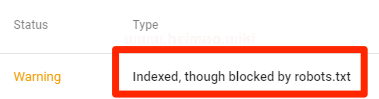
這表示雖然有部分內容被robots.txt文件屏蔽了,但仍然可以被谷歌索引。
如果你希望從搜索引擎索引庫中刪除該內容,robots.txt文件指令并不是最好的辦法,可使用meta robots標簽、或者是x-robots HTTP頭部指令防止頁面被搜索蜘蛛索引。
如果你是不小心將該內容屏蔽了,并且希望該內容重新被搜索引擎索引,只需要在robots.txt文件中刪除相關指令就行了,這樣就可以讓該內容展示在搜索引擎中了。
FAQs
以下是站長朋友們經常問的問題,如果下方問題并沒有包含你所需要解答的問題,歡迎大家在下方評論區別留下你的問題,黑帽百科會及時給大家解答。
1)robots.txt文件大小最大為多少?
約為500 千字節。
2)WordPress中的robots.txt在哪里?
robots.tx文件在網站根目錄下,例: 域名.com/robots.txt.
3)如何在Wordpress當中編輯robots.txt?
你可以手動編輯該文件,也可以使用WordPress相關插件編輯robots.txt文件,直接在WordPress后臺就可以編輯。
4)如果robots.txt文件屏蔽了不想被禁止索引的頁面有哪些影響?
robots.txt文件屏蔽了不想被禁止索引的頁面的影響,要看屏蔽時間的長短,時間長則影響大,時間短則影響小,最后我們只需要改正錯誤的robots指令即可。
5)noindex標記谷歌搜索是否可以識別?
谷歌搜索雖然沒有明確表示可以識別此標簽,但如果此頁面你不想被搜索蜘蛛索引,你可以將noindex標簽放在頁面中,這樣谷歌識別出了這個標記,就不會收錄該頁面。
最后的想法
robots.txt文件雖然看上去簡單,但卻是最容易出錯的,一旦出錯對網站SEO優化的影響將是非常嚴重的,甚至造成這個網站直接廢掉。